Here is a guide on how to set up and use the s3cmd command line tool, after following this guide you will be in a position to be able to use s3cmd to manage your AWS S3 buckets and files.
Why use a CLI tool?
I host websites on a few self-hosted web servers, the reason why I’m using a CLI tool like s3cmd is to make it easier to back up website configuration and database data files.
This command can be used in conjunction with a script that runs on a cronjob that will allow me to set up periodic backups in case of a worst-case scenario where I close access to my web server and have to set it up again.
Why not use AWS CLI?
The official Amazon AWS tool named AWS CLI can be used to connect to S3 as well but it also can be used to connect to a lot of other services that Amazon AWS provides. For my current purpose, all I require is to backup files to the AWS S3 service so as of right now I will use the s3cmd tool.
There will be an opportunity later on for me to try out AWS CLI whereby I will write up a blog post on my experience using that tool as well.
Installation
Follow either of the following steps to install s3cmd.
Install on macOS
The AWS S3 tool can be installed via brew.
brew install s3cmd
After installation try running the version command to see if it’s working.
s3cmd --version
Install on Linux
The following install command is for Ubuntu as it uses the APT package manager.
sudo apt install -y s3cmd
Output the version to verify it’s installed.
s3cmd --version
Connecting your AWS account
The next step is connecting the s3cmd tool to your Amazon AWS account.
Log in to your Amazon AWS account and select the IAM service.
On the IAM dashboard, there is a Manage access keys section that can be used to create a new Access and Secret key which requires connecting your AWS account outside the account.
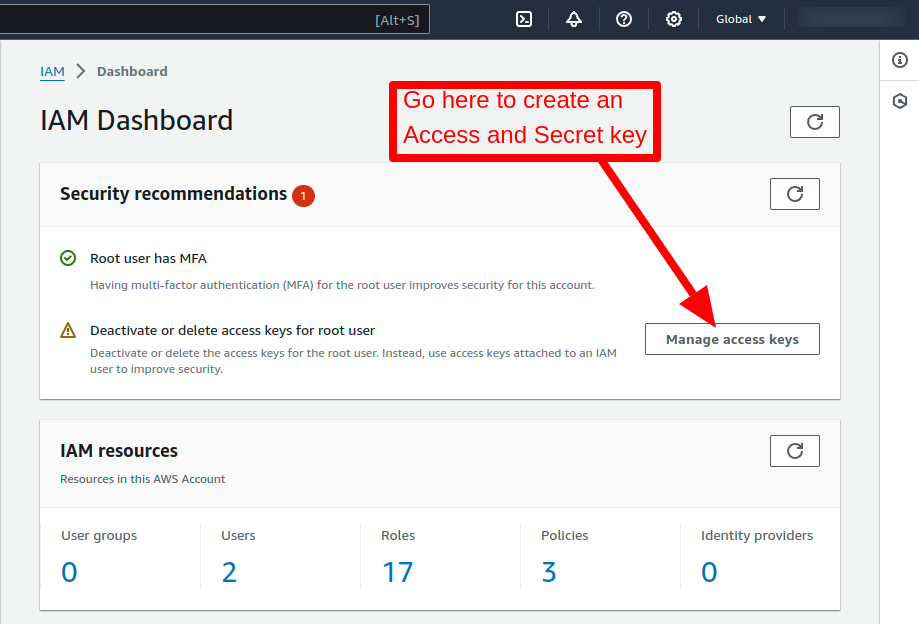
After creating the keys you can now use them to set up the configuration for the s3cmd command.
Run the following command to start.
s3cmd --configure
You will be prompted with a series of questions, here is a breakdown of them.
Also to use the default option (default option is shown in square brackets) just press the Enter key.
Access Key
Copy and paste your access key.
Secret Key
Copy and paste your secret key.
Default Region [US]
Use the default option US or other region, for my setup I used EU.
S3 Endpoint [s3.amazonaws.com]
DNS-style bucket+hostname:port template for accessing a bucket [%(bucket)s.s3.amazonaws.com]
Path to GPG program [/usr/bin/gpg]
Use HTTPS protocol [Yes]
HTTP Proxy server name
Use the default option for all of the above questions.
Save settings? [y/N]
Type y and press Enter
After going through the process s3cmd is available to use to manage your S3 buckets and files.
Usage
Here are common commands that can be used.
Please Note: Replace the square bracket values with the values to be used.
To list all the buckets.
s3cmd ls
To list all contents of a bucket.
Example
s3cmd ls s3://meshu
s3cmd ls [BUCKET URL]
To upload a file to a bucket.
Example
s3cmd put ./image.png s3://meshu
s3cmd put [FILENAME] [BUCKET URL]
The issue using the s3cmd get command
I encountered issues using the get command to download files as I would get the following error.
ERROR: S3 error: 400 (Bad Request)
An alternative solution is to use the sync command to download the file to my local system instead of using the get command.
To sync between local and S3 and vice versa.
Example: s3cmd sync s3://meshu/image.png image2.png
s3cmd sync [BUCKET URL] [LOCAL FILENAME]
You can also sync the other way, sync a local file to an S3 file.
s3cmd sync [LOCAL FILENAME] [BUCKET URL]